源码阅读:Harbor-Operator
Table of contents
开始前的准备
为什么是 Harbor-Operator
Worse is Better?
什么是好的软件?
在 80 年代末一篇著名的文章 The Rise of Worse is Better 中,作者提到良好的软件设计应当考虑 简单、正确、一致、完整 这四种特质。
文中作者提到了两种软件设计理念,暂且叫做 the right thing 和 worse is better(有必要指出这个命名并非贬义);这两种设计理念都是围绕着上述的四种特质展开的,区别在于对这些特质的优先级排序。
The right thing
- 简单 - 设计必须简单易懂,接口简单比实现简单更为重要
- 正确 - 设计必须正确,这一点不能有任何让步
- 一致 - 一致和正确一样重要,因此简单性和完整性可以稍作让步
- 完整 - 设计必须能够考虑到各种各样可能出现的情况,不能为了保持简单而过度牺牲完整性
Worse is better
- 简单 - 设计必须简单易懂,实现简单比接口简单更为重要,简单性是最重要的特质
- 正确 - 设计必须正确,当然保持简单比正确更重要一点
- 一致 - 设计不能过于不一致,为了保持简单可以牺牲一致性,在保证简单的情况下可以为了完整性而牺牲一致性
- 完整 - 设计必须能够考虑到各种各样可能出现的情况,可以随时牺牲完整性来保证设计简单
随后作者举了两者的许多例子来论证为什么 worse-is-better 正在席卷当时的软件行业。
这两种理念不存在优劣之分,如今我们也身边,而实际情况也往往游走于两者之间,我们希望能够做出优秀的,具备美学价值的设计,但也必须考虑成本和人的因素,最终要交付质量达标的,可工作的软件来解决真实世界中的问题,而软件的编写、维护成本绝对不可以大于问题本身的价值。
Golang - the language
Golang 几乎可以说是 worse is better 理念的典范:
- 它凝聚了 Google 多年来在 C++ 上的实践经验
- 它是如此简单,没有任何复杂特性,因此解决一个问题基本只有一种 building block,这就意味着:
- 几乎不需要在语言本身上下任何功夫就能轻易掌握
- 代码非常好读
- 编译迅速,甚至为编译速度舍弃了泛型
- 可以十分容易地通过 goroutine 跑并行任务
- 几乎舍弃了异常栈这个语言特性,强制错误检查和处理
- 一次编译,到处运行
Kubernetes - the platform
Kubernetes 大家都很熟悉我就不班门弄斧了,一句话带过:它提供了一套概念上非常简单的 API 设计,辅以来自控制论的调谐机制,使得容器化的软件得以在其中自动化部署,扩展和运维。
k8s 通过开放这套 API 规范和调谐机制允许开发者对其能力进行扩展,开发者得以实现 Operator Pattern:将软件的配置、部署(Day-1)和运维、备份、故障转移(Day-2)知识编写成用于操作软件的软件将这些复杂易错的操作自动化,从而提高可靠性,并降低成本。
那么选择 Harbor Operator 的原因就是它具备非常优秀的设计,在一个优秀的平台上和通过简单语言特性,没有过多的奇淫巧技,通过几个关键的,符合 SOLID 设计原则的设计实现了一套务实且具备美学价值的软件系统,可以被视为是 the right thing 理念的实践者。
作者的代码几乎没有注释,但异常好读,这也有赖于整个系统的
目标
抽象简化问题的同时必然伴随着灵活性的牺牲,而 Harbor Operator 则完全舍弃了灵活性以求带来最大程度的思维减负,使得 Operator 的开发更像是声明一份软件配置。
使用 client-go 手写 operator 得益于 golang 泛型的缺失简直就是找罪受,整个项目中会充斥着巨量的 boilerplate code(模板代码),我相信即使是真的用 client-go 手写也没人会真的从头写起。
于是 kubebuilder 应运而生,它将 Kubernetes Client 的创建,监听 Kubernetes API Server 的请求以及到请求的队列化等操作抽象成公共库 controller runtime,和公共工具 controller tools,并能够为开发者生成脚手架代码专注于处理 API 对象变更请求的业务逻辑开发的工作上。
Kubebuilder 依然为业务逻辑的多样性保留了一丝净土,而 Harbor Operator 在此基础上进一步追求极致,完全牺牲了灵活性以追求概念的一致和简单,而它面临的业务也确实十分适合这种做法。
因此,在本次源码阅读中,我们的主要目标是要学习 Harbor Operator:
- 如何进行 Day-1 操作
- 如何进一步减少 operator 代码的冗余程度,使用同一套 Controller 代码实现十一个不同层次 CRD 的 Controller
- 如何利用 DAG 解决资源间的依赖问题,作者似乎还为此申请了专利
此外,我们不会着重研究:
- Harbor Operator 中的 Day-2 操作,实际上当前版本这部分功能还不稳定
- Harbor 本身的源码和功能
源码阅读
静态结构
目录结构
这里只列出了目录
root
├── apis
│ ├── goharbor.io
│ │ └── v1alpha3
│ └── meta
│ └── v1alpha1
├── controllers
│ ├── controller_string.go
│ ├── controllers.go
│ └── goharbor
│ ├── chartmuseum
│ ├── controller_test.go
│ ├── core
│ ├── exporter
│ ├── harbor
│ ├── harborcluster
│ ├── internal
│ ├── jobservice
│ ├── notaryserver
│ ├── notarysigner
│ ├── portal
│ ├── registry
│ ├── registryctl
│ └── trivy
├── pkg
│ ├── builder
│ ├── cluster
│ │ ├── controllers
│ │ │ ├── cache
│ │ │ ├── common
│ │ │ ├── database
│ │ │ │ └── api
│ │ │ ├── harbor
│ │ │ └── storage
│ │ ├── gos
│ │ ├── k8s
│ │ └── lcm
│ ├── config
│ │ ├── harbor
│ │ └── template
│ ├── controller
│ │ ├── errors
│ │ ├── internal
│ │ │ └── graph
│ │ └── mutation
│ ├── event-filter
│ ├── exit
│ ├── factories
│ │ ├── application
│ │ ├── logger
│ │ └── owner
│ ├── graph
│ ├── harbor
│ ├── image
│ ├── manager
│ ├── resources
│ │ ├── checksum
│ │ └── statuscheck
│ ├── scheme
│ ├── setup
│ ├── status
│ ├── template
│ ├── tracing
│ ├── utils
│ │ └── strings
│ └── version
...
关键接口

系统架构
截至 v1.0.1 Harbor Operator 目前主要负责 Harbor 系统的 Day-1 操作 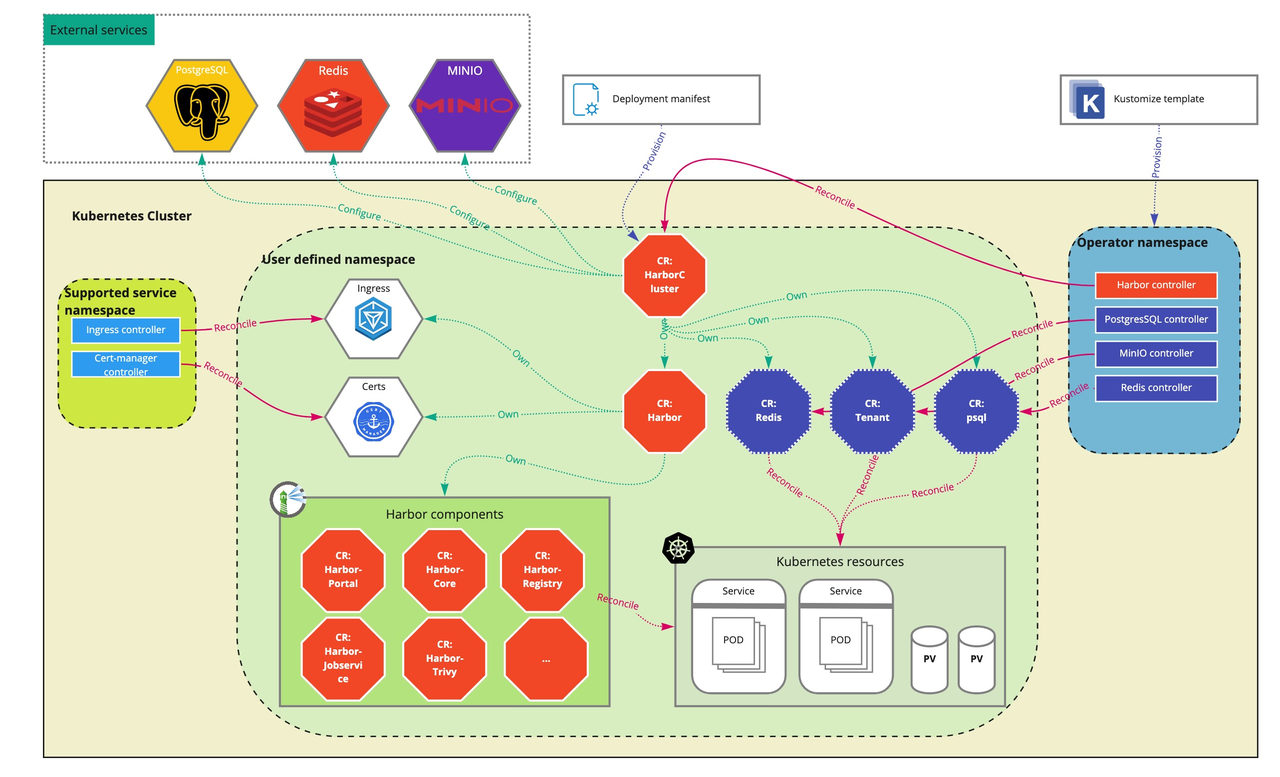
抓大放小:HarborCluster
首先让我们来过滤掉一些不是很关键的部分:HarborCluster 这个 CRD 以及其 Controller 的实现。
为什么说它特殊呢?首先观察它在系统架构中的位置:处于最上层,它管理着 Harbor 系统本身和其所依赖的所有有状态服务,这需要从项目历史和它自身在系统架构中的特殊地位两方面说起了。
从系统架构层面看来,这个 HarborCluster CRD 从定义上看和 Harbor CRD 有着极大的相似性,代码存在大量冗余,显得十分不好看,这是由于它作为整个系统中最上(外)层 CRD,直接面向用户;必须能够为用户提供声明 Harbor 部署的所有必要配置项,此外由于 Harbor 自己是一套无状态服务,因此完整的部署也要求 HarborCluster CRD 管理 Harbor 系统所依赖的所有有状态服务,包括 Postgres, Minio 和 Redis。
而 Harbor 系统自身的必要信息已经在 Harbor CRD 中定义好了,因此 HarborCluster CRD 中的冗余部分就是要将这些信息完整无误的传递给 Harbor CRD;此外 HarborCluster CRD 还需要管理那些处于自身职责边界之外的有状态服务的 CRD,因此不能够完全使用 Harbor 以及 Harbor 所有子组件中的 Controller 逻辑。
从历史层面看来,Harbor Operator 最初是 OVH Cloud 的私有项目,后来才被捐赠给 goharbor 社区,因此结合 git history 观察,HarborCluster 的 CRD 定义和其 Controller 的实现与系统中其他 Controller 有如此大的不一致性的原因在于它是社区贡献的后来者,在 Harbor Operator 设计之初并没有考虑到它所肩负的功能。
而 HarborCluster Controller 本身实现和我们平时见到的大多数使用 Controller-runtime 实现的 Controller 没什么太大的区别,因此不做详细研究。
HarborCluster Controller

Harbor Core Controller

解决资源间的依赖关系: Dependency Graph
依赖图是整个项目中较为独立的一个模块,但它实际上承担着 Harbor Operator 中所有 controller 的执行引擎的作用。本质上是观察到 Kubernetes 中各类资源之间存在相互依赖关系,一些资源的部署和调谐有赖于其他一些资源的部署和调谐,比如 Deployment 可能会依赖 Configmap;最终这些依赖关系构成了一张依赖图,实际上这个图应该是一个 DAG。在这里我们需要接口定义如下:
package graph
type Resource interface{}
type RunFunc func(context.Context, Resource) error
type Manager interface {
Run(ctx context.Context) error
AddResource(ctx context.Context, resource Resource, blockers []Resource, run RunFunc) error
}
type resourceManager struct {
resources map[Resource][]Resource
functions map[Resource]RunFunc
lock sync.Mutex
}
- 其中 Resource 定义了一个抽象的资源,由于这个模块不关注资源究竟代表着什么,同时为了在语言表达力的限制下最大程度保留灵活性,因此使用顶类型 interface{}。
- RunFunc 负责具体处理如何针对一个 Resource 进行操作,这里 RunFunc 需要面对一个类型安全性的问题:interface{}意味着编译器对该类型一无所知,也就无从下手,但 RunFunc 必须拿着这个可以是任何东西的类型去做点什么,因此我们认为它必须进行类型强转,如果每个资源的 RunFunc 都要手动地强转成具体的类型,就非常无趣且令人作呕了;稍后我们观察一下 Harbor Operator 是如何把脏活集中到一个地方的。
- Manager 只有两个 Method: 添加 Resource,和运行这个图,需要分别研究一下。
- 实现了 Manager 的 resourceManager 数据结构定义也很简单:
- 一个 resource -> blockers 的 map
- 一个 resource -> runFunc 的 map
- 一个 lock 用来处理对于 map 操作的并发性,从这里我们可以看出来作者并不喜欢 Sync Map 这类保证了并发安全却失去了类型安全的数据结构,这就更令人好奇作者是如何处理那么多个(11 个组件)的 RunFunc 的。
既然是 Graph 总要有 Graph 的数据结构以及 build 这个 Graph 的工厂方法,resourceManager 的数据结构看起来有点生硬,不确定是否就是真正的 Graph。
AddResource
根据签名可以观察到 AddResource 添加了需要被添加的资源本身和它所有的依赖项以及相应的 runFunc,值得注意的点在于必须先添加不依赖任何资源的资源(即出度为 0)。
func (rm *resourceManager) AddResource(ctx context.Context, resource Resource, blockers []Resource, run RunFunc) error {
if resource == nil {
return nil
}
if run == nil {
return errors.Errorf("unsupported RunFunc value %v", run)
}
span, _ := opentracing.StartSpanFromContext(ctx, "addResource", opentracing.Tags{
"Resource": resource,
})
defer span.Finish()
nonNilBlockers := []Resource{}
for _, blocker := range blockers {
if blocker == nil {
continue
}
nonNilBlockers = append(nonNilBlockers, blocker)
_, ok := rm.resources[blocker]
if !ok {
return errors.Errorf("unknown blocker %+v", blocker)
}
}
rm.lock.Lock()
defer rm.lock.Unlock()
_, ok := rm.resources[resource]
if ok {
return errors.Errorf("resource %+v already added", resource)
}
rm.resources[resource] = nonNilBlockers
rm.functions[resource] = run
return nil
}
Run
这个包中几乎所有重要的逻辑都在 Run 这个 Method 中,先看它的前半部分:
func (rm *resourceManager) Run(ctx context.Context) error {
span, ctx := opentracing.StartSpanFromContext(ctx, "walkGraph", opentracing.Tags{
"Nodes.count": len(rm.resources),
})
defer span.Finish()
g := errgroup.Group{}
l := logger.Get(ctx)
for _, no := range rm.getGraph(ctx) {
...
出现了!getGraph,看起来像是要 build 这个 graph,跟进去发现果然 resourceManager 只是个 builder,真正的 graph 藏在这里面,使用邻接链表表达的,乍一看甚至很复杂:
type node struct {
resource Resource
fn RunFunc
parent chan error
parentLock *sync.Mutex
parentCount int
children []chan<- error
childrenLock []*sync.Mutex
}
func (no *node) Wait(ctx context.Context) error {...}
func (no *node) Terminates(err error) (result error) {...}
func (no *node) AddChild(child *node) {...}
Parent 和 children 为什么是一个 channel,为什么需要那么多 lock;还是观察一下 graph 的构建过程:
func (rm *resourceManager) getGraph(ctx context.Context) []*node {
span, _ := opentracing.StartSpanFromContext(ctx, "getGraph")
defer span.Finish()
rm.lock.Lock()
defer rm.lock.Unlock()
graph := make(map[Resource]*node, len(rm.resources))
result := make([]*node, len(rm.resources))
i := 0
for resource, blockers := range rm.resources {
blockerCount := len(blockers)
node := &node{
resource: resource,
fn: rm.functions[resource],
parent: make(chan error, blockerCount),
parentLock: &sync.Mutex{},
parentCount: blockerCount,
children: []chan<- error{},
childrenLock: []*sync.Mutex{},
}
graph[resource] = node
result[i] = node
i++
blockers := blockers
defer func() {
for _, blocker := range blockers {
graph[blocker].AddChild(node)
}
}()
}
return result
}
原来依赖关系被倒转了,现在是被依赖项指向依赖方,对于每个资源都构造一个 node,同时对于资源的每一个依赖项,都将这个资源的 parent chan 添加到依赖项的 children 中,最终的 graph 就是 node 的集合。
这么做其实难免令人一头雾水,那么再观察一下执行过程:
for _, no := range rm.getGraph(ctx) {
no := no
g.Go(func() (err error) {
defer func() {
err := no.Terminates(err)
if err != nil {
l.Error(err, "failed to terminate node when running graph")
}
}()
err = no.Wait(ctx)
if err != nil {
return err
}
err = no.fn(ctx, no.resource)
return err
})
}
非常地简单粗暴,对于每一个 node 都等待其入度 node 执行完毕后执行其自己的 runFunc,并把潜在的错误传播给其链路后方所有等待执行的 node 提前中止。
这里我十分不理解为什么不用一个拓扑排序来解决这种定义良好的经典问题。
初始化
GraphManager 的初始化使用的是一个 thread local 的全局变量,初始化之后扔到空中(ctx),是各类 api framework 的常见依赖注入方式;
func (c *Controller) NewContext(req ctrl.Request) context.Context {
ctx := context.TODO()
application.SetName(&ctx, c.GetName())
application.SetVersion(&ctx, c.GetVersion())
application.SetGitCommit(&ctx, c.GetGitCommit())
ctx = sgraph.WithGraph(ctx)
logger.Set(&ctx, c.Log.WithValues("request", req))
return ctx
}
func WithGraph(ctx context.Context) context.Context {
return context.WithValue(ctx, &graphKey, graph.NewResourceManager())
}
func Get(ctx context.Context) graph.Manager {
g := ctx.Value(&graphKey)
if g == nil {
return nil
}
return g.(graph.Manager)
}
将代码复用率提高到极致:Controller
除了之前被我们摘掉的 HarborCluster Controller 之外,Harbor Operator 中所有组件的 Controller 都直接组合了这同一个 Controller,抽离出所有 Controller 的公共逻辑,使用同一个 Run,同一个 Reconcile,怎么做到的?
- 抽取了哪些逻辑
- 如何处理不同点
- 牺牲了什么东西
数据结构
Controller 对于接口的实现除了实现了 Reconciler 之外没什么有意思的;那么先来看看 Controller 的数据结构定义:
type ResourceManager interface {
AddResources(context.Context, resources.Resource) error
NewEmpty(context.Context) resources.Resource
}
type Controller struct {
client.Client
BaseController controllers.Controller
Version string
GitCommit string
ConfigStore *configstore.Store
rm ResourceManager
Log logr.Logger
Scheme *runtime.Scheme
}
我们不太认识的东西只有 BaseController 和 rm
跟过去看 BaseController 基本上是个身份标识符,用于标识 Controller 自身的信息和一些 Label 信息,那么不同 Controller 之间不同的逻辑差异点只可能存在于 ResourceManager 之中,ResourceManager 看上去也是一个很简单的接口,实现了 ResourceManager 的果然就是各个具体的 Controller;我们将在最后研究 ResourceManager 的具体例子。
type Controller int
const (
Core Controller = iota // core
JobService // jobservice
Portal // portal
Registry // registry
RegistryController // registryctl
ChartMuseum // chartmuseum
Exporter // exporter
NotaryServer // notaryserver
NotarySigner // notarysigner
Trivy // trivy
Harbor // harbor
HarborCluster // harborcluster
HarborConfiguration // harborconfiguration
)
func (c Controller) GetFQDN() string {
return fmt.Sprintf("%s.goharbor.io", strings.ToLower(c.String()))
}
func (c Controller) Label(suffix ...string) string {
return c.LabelWithPrefix("", suffix...)
}
func (c Controller) LabelWithPrefix(prefix string, suffix ...string) string {
var suffixString string
if len(suffix) > 0 {
suffixString = "/" + strings.Join(suffix, "-")
}
if prefix != "" {
prefix = "." + prefix
}
return fmt.Sprintf("%s%s%s", prefix, c.GetFQDN(), suffixString)
}
Reconcile 逻辑
那么 Controller 是如何做到只使用一个 Reconcile 就可以 reconcile harbor 全家十一个 CRD 连同那么多系统资源的呢?
根据上面我们已经知道的信息,应该是对于每个 CRD 都使用了一个 ResourceManager 来定义这个 CRD 需要创建和调谐的各种资源,而这些资源通过依赖图来定义其依赖关系,并为每个 CRD 都写一个具体的 RunFunc 来完成最终的调谐。
func (c *Controller) Reconcile(req ctrl.Request) (ctrl.Result, error) {
ctx := c.NewContext(req)
span, ctx := opentracing.StartSpanFromContext(ctx, "reconcile", opentracing.Tags{
"resource.namespace": req.Namespace,
"resource.name": req.Name,
"controller": c.GetName(),
})
defer span.Finish()
l := logger.Get(ctx)
// Fetch the instance
object := c.rm.NewEmpty(ctx)
ok, err := c.GetAndFilter(ctx, req.NamespacedName, object)
if err != nil {
// Error reading the object
return ctrl.Result{}, err
}
if !ok {
// Request object not found, could have been deleted after reconcile request.
// Owned objects are automatically garbage collected. For additional cleanup logic use finalizers.
l.Info("Object does not exists")
return ctrl.Result{}, nil
}
if !object.GetDeletionTimestamp().IsZero() {
logger.Get(ctx).Info("Object is being deleted")
return ctrl.Result{}, nil
}
owner.Set(&ctx, object)
if err := c.Run(ctx, object); err != nil {
return c.HandleError(ctx, object, err)
}
return ctrl.Result{}, c.SetSuccessStatus(ctx, object)
}
很经典的 Reconcile 逻辑,看来花样都在 c.Run 里:
func (c *Controller) Run(ctx context.Context, owner resources.Resource) error {
span, ctx := opentracing.StartSpanFromContext(ctx, "run")
defer span.Finish()
logger.Get(ctx).V(1).Info("Reconciling object")
if err := c.rm.AddResources(ctx, owner); err != nil {
return errors.Wrap(err, "cannot add resources")
}
if err := c.PrepareStatus(ctx, owner); err != nil {
return errors.Wrap(err, "cannot prepare owner status")
}
return sgraph.Get(ctx).Run(ctx)
}
果然 rm 在这里出现了,添加某个具体的 Controller 所需要的资源之后,那么 PrepareStatus 看起来是统一的一个,结合这个 method 源码和 CRD 定义发现它假设所有组件都具备同样的 Status,又是一个牺牲了灵活性换取简单和一致性的设计,实际上这个设计遵循了 K8s 提倡的规范,可以在设计 CRD 时加以参考,这里不再赘述。
最后一行:sgraph.Get(ctx).Run(ctx),依赖图来了,从空中(ctx)抓下来,至此这部分逻辑闭环了,还剩下的问题是:实现了 ResourceManager 的各个 Concrete Controller 如何构造依赖图,并构造自己的 RunFunc 呢?
代码即配置:ResourceManager
最后一步可以说是水到渠成。
所有实现了 ResourceManager 的 Controller 地位上应该都是平等的,我们借助 harbor core 这一个例子来一探究竟。
除了用来生成具体 K8s 资源的部分之外,应该关注的是实现了 ResourceManager 接口的部分;
func (r *Reconciler) NewEmpty(_ context.Context) resources.Resource {
return &goharborv1.Core{}
}
func (r *Reconciler) AddResources(ctx context.Context, resource resources.Resource) error {
core, ok := resource.(*goharborv1.Core)
if !ok {
return serrors.UnrecoverrableError(errors.Errorf("%+v", resource), serrors.OperatorReason, "unable to add resource")
}
service, err := r.GetService(ctx, core)
if err != nil {
return errors.Wrap(err, "cannot get service")
}
_, err = r.Controller.AddServiceToManage(ctx, service)
if err != nil {
return errors.Wrapf(err, "cannot add service %s", service.GetName())
}
configMap, err := r.GetConfigMap(ctx, core)
if err != nil {
return errors.Wrap(err, "cannot get configMap")
}
configMapResource, err := r.Controller.AddConfigMapToManage(ctx, configMap)
if err != nil {
return errors.Wrapf(err, "cannot add configMap %s", configMap.GetName())
}
secret, err := r.GetSecret(ctx, core)
if err != nil {
return errors.Wrap(err, "cannot get secret")
}
secretResource, err := r.Controller.AddSecretToManage(ctx, secret)
if err != nil {
return errors.Wrapf(err, "cannot add secret %s", secret.GetName())
}
deployment, err := r.GetDeployment(ctx, core)
if err != nil {
return errors.Wrap(err, "cannot get deployment")
}
_, err = r.Controller.AddDeploymentToManage(ctx, deployment, configMapResource, secretResource)
if err != nil {
return errors.Wrapf(err, "cannot add deployment %s", deployment.GetName())
}
err = r.AddNetworkPolicies(ctx, core)
return errors.Wrap(err, "network policies")
}
好家伙,除了资源要按照顺序添加之外,这就相当于是一个声明式设计了;如果想添加新的 Controller 简直易如反掌:只要知道这个 Controller 要对什么资源调谐就好,不需要管理具体的 Reconcile 逻辑了。
等等,难道 RunFunc 不需要我们亲自实现吗?这就是我们本次源码阅读的最后一个问题,看看 harbor operator 如何将任意 Resource 的 Reconcile 过程泛化并抽象成单一函数。
那么比如说这里有一个 r.Controller.AddServiceToManage(ctx, service)
func (c *Controller) AddServiceToManage(ctx context.Context, resource *corev1.Service, dependencies ...graph.Resource) (graph.Resource, error) {
if resource == nil {
return nil, nil
}
mutate, err := c.GlobalMutateFn(ctx)
if err != nil {
return nil, err
}
res := &Resource{
mutable: mutate,
checkable: statuscheck.True,
resource: resource,
}
g := sgraph.Get(ctx)
if g == nil {
return nil, errors.Errorf("no graph in current context")
}
return res, g.AddResource(ctx, res, dependencies, c.ProcessFunc(ctx, resource, dependencies...))
}
有意思的地方有两处:
Resource 定义,这个我们之前没见过
Graph AddResource 的调用出现了,我们关心的 RunFunc 的构造就在这里,稍后做研究。
先来看这个 Resource,记得在 Graph 中,由于不关心 Resource 具体是什么,因此在那里给了一个 interface{},这里对于 Resource 比较关心,因此比较重要:
package controller
type Resource struct {
mutable resources.Mutable
checkable resources.Checkable
resource resources.Resource
}
package resources
type Mutable func(context.Context, runtime.Object) error
func (m *Mutable) AppendMutation(mutate Mutable) {
old := *m
*m = func(ctx context.Context, resource runtime.Object) error {
if err := old(ctx, resource); err != nil {
return err
}
return mutate(ctx, resource)
}
}
func (m *Mutable) PrependMutation(mutate Mutable) {
old := *m
*m = func(ctx context.Context, resource runtime.Object) error {
if err := mutate(ctx, resource); err != nil {
return err
}
return old(ctx, resource)
}
}
type Resource interface {
runtime.Object
metav1.Object
}
type Checkable func(context.Context, runtime.Object) (bool, error)
看得出,本质上是对 K8s generic resource,在此之上 Harbor Operator 做了一些额外的封装。
这些额外的封装分别是 checkable 和 mutable。
其中 checkable 定义了 resource 合法性的检查,比较简单。
Mutable 看着很花,实际上就是简单的 Monad Composition;
Mutable 构成了一个 Monad,和函数 composition 不同的是,每一次 compose 之后计算结果都会产生一个额外的结果用来表达计算副作用,因此无法直接连续应用 function,在一些函数式语言中提供了 fish operator >=> 来实现 Monad Compose。
使用 scala 语法描述的 fish operator 签名如下
def >=>[A, B, C](f: A => M[B], g: B => M[C]): A => M[C]
讲人话就是 mutable 数据结构允许将许多个 mutation function 以一定顺序组合起来,在遇到报错时,直接退出。
至此,研究如何构造 RunFunc 的前置条件已经齐全了,最后让我们看看 harbor operator 是如何利用这些前置条件为各个毫不相同的 Resource 通过通一套逻辑构造出 Reconcile 的具体实现。
最后的迷团:ProcessFunc
ProcessFunc 本质上是一个高阶函数,利用闭包捕获一个 depManager,主要是用于计算和更改资源本身和它的各项依赖的 Checksum。
构造出来的 RunFunc,先检查资源以及其依赖是否改变,如果没有改变直接检查一下 ready 就完事;否则更新 Checksum 供下次检查之后再去调用 c.applyAndCheck 真正 Reconcile Change。
func (c *Controller) ProcessFunc(ctx context.Context, resource runtime.Object, dependencies ...graph.Resource) func(context.Context, graph.Resource) error { // nolint:funlen
depManager := checksum.New(c.Scheme)
depManager.Add(ctx, owner.Get(ctx), true)
gvks, _, err := c.Scheme.ObjectKinds(resource)
if err == nil {
resource.GetObjectKind().SetGroupVersionKind(gvks[0])
}
for _, dep := range dependencies {
if dep, ok := dep.(*Resource); ok {
gvks, _, err := c.Scheme.ObjectKinds(dep.resource)
if err == nil {
dep.resource.GetObjectKind().SetGroupVersionKind(gvks[0])
}
depManager.Add(ctx, dep.resource, false)
}
}
return func(ctx context.Context, r graph.Resource) error {
res, ok := r.(*Resource)
if !ok {
return nil
}
span, ctx := opentracing.StartSpanFromContext(ctx, "process")
defer span.Finish()
namespace, name := res.resource.GetNamespace(), res.resource.GetName()
gvk := c.AddGVKToSpan(ctx, span, res.resource)
l := logger.Get(ctx).WithValues(
"resource.apiVersion", gvk.GroupVersion(),
"resource.kind", gvk.Kind,
"resource.name", name,
"resource.namespace", namespace,
)
logger.Set(&ctx, l)
span.
SetTag("resource.name", name).
SetTag("resource.namespace", namespace)
changed, err := c.Changed(ctx, depManager, res.resource)
if err != nil {
return errors.Wrap(err, "changes detection")
}
if !changed {
l.V(0).Info("dependencies unchanged")
err = c.EnsureReady(ctx, res)
return errors.Wrap(err, "check")
}
res.mutable.AppendMutation(func(ctx context.Context, resource runtime.Object) error {
if res, ok := resource.(metav1.Object); ok {
depManager.AddAnnotations(res)
}
return nil
})
err = c.applyAndCheck(ctx, r)
return errors.Wrapf(err, "apply %s (%s/%s)", gvk, namespace, name)
}
}
实际上的 Reconcile 逻辑就在 applyAndCheck 中,这就使用了之前在 Resource 中注册的 mutable function。
func (c *Controller) applyAndCheck(ctx context.Context, node graph.Resource) error {
span, ctx := opentracing.StartSpanFromContext(ctx, "applyAndCheck")
defer span.Finish()
res, ok := node.(*Resource)
if !ok {
return serrors.UnrecoverrableError(errors.Errorf("%+v", node), serrors.OperatorReason, "unable to apply resource")
}
err := c.Apply(ctx, res)
if err != nil {
return errors.Wrap(err, "apply")
}
err = c.EnsureReady(ctx, res)
return errors.Wrap(err, "check")
}
func (c *Controller) Apply(ctx context.Context, res *Resource) error {
span, ctx := opentracing.StartSpanFromContext(ctx, "apply")
defer span.Finish()
l := logger.Get(ctx)
l.V(1).Info("Deploying resource")
resource := res.resource
if err := res.mutable(ctx, resource); err != nil {
return errors.Wrap(err, "mutate")
}
err := c.Client.Patch(ctx, resource, client.Apply, &client.PatchOptions{
Force: &force,
FieldManager: application.GetName(ctx),
})
if err != nil {
l.Error(err, "Cannot deploy resource")
if apierrs.IsForbidden(err) {
return serrors.RetryLaterError(err, "dependencyStatus", err.Error())
}
if apierrs.IsInvalid(err) {
return serrors.UnrecoverrableError(err, "dependencySpec", err.Error())
}
return err
}
return nil
}
在所有操作都做完之后,调用 c.EnSureReady 调用之前注册的 checkable 完成 Reconcile 的的过程。
至此,Harbor Operator 代码中我们关心的重要设计已经研究完毕,令人叹为观止。